
الگوریتم تشخیص مقاله نوشته شده با هوش مصنوعی؛ شناساگرها چطور کار میکنند؟

اگر اهل نگارش مقالههای دانشگاهی باشید یا برای مقاله پایان نامهی مقطع ارشد یا دکترا در نظر دارید نوشتن مقاله را شروع کنید، احتمالا بارها وسوسه شدهاید که از برنامههای هوش مصنوعی کمک بگیرید اما همانطور که احتمالا میدانید، ژورنالهای خارجی به راحتی متوجه میشوند که مقالهی شما توسط هوش مصنوعی نوشته شده است. در این مقاله قصد داریم به این سوال بپردازیم که چطور ژورنالها این قدرت را دارند تا مچ نویسندگان را بگیرند و دقیقا الگوریتم تشخیص مقاله توسط نرمافزارهای شناساگر هوش مصنوعی چیست.

هوش مصنوعی مولد (Generative AI) میتواند ابزاری قدرتمند برای تحقیق باشد، اما محققان باید آن را به طور اخلاقی و شفاف به کار ببرند. سردبیران و داوران مجلات باید از تحولات در فناوریهای هوش مصنوعی به خوبی آگاه باشند تا بتوانند به طور موثر مقالات نوشته شده توسط هوش مصنوعی را شناسایی کنند. ابزارهای تشخیصی زیادی مثل GPT Zero در اختیار سردبیرها و انتشارات قرار میگیرد که به راحتی حتی یک پاراگراف نوشته شده توسط هوش مصنوعی را شناسایی میکنند. سوال دقیقا اینجاست که چه الگوریتمی توسط هوش مصنوعیهای مولد اجرا میشود که ابزارهای تشخیصدهنده به سادگی و در کسری از ثانیه میتوانند این موارد را شناسایی کرده و نویسندگان را رسوا کند.
فهرست محتوا
چطور بفهمیم یک مطلب را هوش مصنوعی نوشته؟
به الگوها یا تکرارها توجه کنید
انسجام را بسنجید
جزئیات و حقایق را بررسی کنید.
فقدان احساسات در متن
سابقه نویسنده را بررسی کنید
فاکتورهای احتمالی داورهای ژورنالهای خارجی برای الگوریتم تشخیص مقاله
سبکهای نوشتاری غیرمعمول یا مشکوک
عدم اصالت
محتوا و نتایج علمی نادرست
چند الگوریتم تشخیص مقاله مهم توسط نرمافزارهای شناساگر هوش مصنوعی
۱. طبقهبندیکنندهها (Classifiers)
۲. نمایهسازیها (Embeddings)
۳. مولفهای به اسم پرپلکسیتی (Perplexity)
۴. مولفه Burstiness
آیا حافظه موقت هوش مصنوعی در اختیار کسی قرار میگیرد؟
الگوریتمهای هوش مصنوعی برای تشخیص تصاویر و نمودارهای مقاله دانشگاهی
ناهماهنگیهای داده
ناهنجاریهای بصری
ناهماهنگیهای زمینهای
تحلیل متاداده
مقایسه با دانش موجود
ابزارهای شناساگر محتوای هوش مصنوعی چقدر دقیق هستند؟
چطور بفهمیم یک مطلب را هوش مصنوعی نوشته؟
با کیفیت نتایج تولید شده توسط جدیدترین مدلهای هوش مصنوعی، تشخیص مقالات تولید شده توسط هوش مصنوعی میتواند واقعا چالشبرانگیز باشد. با این حال، با یک چشم تیزبین و بازرسی دقیق میتوان نشانههای مشخص را شناسایی کرد.


به الگوها یا تکرارها توجه کنید
شاید واضحترین نشانهی محتوای تولید شده توسط هوش مصنوعی، تکرار کلمات، عبارات یا جملات باشد. هوش مصنوعی برای شناسایی الگوها طراحی شده و سعی میکند آنها را با دقت تکرار کند. بنابراین، ممکن است همان ساختار جمله به طور منظم در پاراگرافهای مختلف در یک نوشته استفاده شود.

انسجام را بسنجید
مقالات تولید شده توسط هوش مصنوعی ممکن است در نگاه اول منسجم به نظر برسند، اما اگر به دقت نگاه کنید، معمولا مشکلات ساختاری وجود دارد. به عنوان مثال، محتوای نوشته شده توسط هوش مصنوعی اغلب دارای طول جملههای تقریبا یکسان است. همچنین هوش مصنوعی به قوانین گرامر یا نشانهگذاریهای زبان مورد نظر به خصوص فارسی توجه دقیقی ندارد.
جزئیات و حقایق را بررسی کنید.
بسته به موضوع، یک مقاله کاملا تولید شده توسط هوش مصنوعی ممکن است تنها به صورت کلی نوشته شده باشد. به همین دلیل، امکان دارد هوش مصنوعی حقایق و اعداد را نادیده بگیرد. بنابراین وقتی مقالهای را میخوانید، به جزئیات (یا عدم وجود آنها) توجه کنید.
مدلهای زبانی هوش مصنوعی به طور مداوم بهروزرسانی نمیشوند. جدیدترین مدلهای OpenAI تنها روی دادههای سال ۲۰۲۱ و قبل از آن آموزش دیدهاند. بنابراین اگر مقالهای که بررسی میکنید به حقایق و اعداد سالهای اخیر مربوط میشود، ممکن است تشخیص نشانههای هوش مصنوعی دشوار باشد.
با این حال، ابزارهای نگارش هوش مصنوعی برای تولید حقایق و آمار قابل باور طراحی شدهاند. اگر هر گونه ناهماهنگی در آنچه گزارش میشود مشاهده کردید، ممکن است نشانهای باشد که مقاله توسط هوش مصنوعی تولید شده است.

باز شدن در صفحه دیجیکالا
فقدان احساسات در متن
نشانهی دیگر و بارز از محتوای تولید شده توسط هوش مصنوعی، کمبود احساس یا شخصیت در نوشتار است. الگوریتمهای هوش مصنوعی به گونهای طراحی شدهاند که تا حد ممکن کارآمد باشند و نوشتار انسانی را با حداقل تلاش تقلید کنند، بنابراین ممکن است کلمات و عبارات احساسی که جزء جداییناپذیر بیان طبیعی زبان هستند را حذف کنند.
با این حال، مدلهای زبان هوش مصنوعی جدیدتر در تقلید از نوشتار انسانی بهتر عمل میکنند، بنابراین این نکته ممکن است به اندازهی کافی قابل اعتماد نباشد. از همین رو، حتما به دنبال نشانههای دیگر نیز باشید.
سابقه نویسنده را بررسی کنید
اگر نمیتوانید به راحتی تعیین کنید که آیا یک مقاله توسط هوش مصنوعی نوشته شده یا خیر، به سابقهی نویسندهی آن برای اطلاعات بیشتر نگاه کنید. یک جستجوی سریع در گوگل اسکولار میتواند هر کار قبلی که محققین انجام دادهاند را فاش کند. همین امر نشان میدهد محققین قادر به تولید محتوای مورد نظر هستند یا خیر.
آیا کارهای گذشتهی نویسنده با آنچه میخوانید مطابقت ندارد؟ در این صورت احتمال دارد که مقاله توسط هوش مصنوعی نوشته شده باشد. اما این مولفه نباید تنها عاملی باشد که در نظر بگیرید؛ چرا که بسیاری از کارشناسان برای کار خود از نویسندهها یا دانشجوهای متفاوت در رشتههای مختلف کمک میگیرند.
فاکتورهای احتمالی داورهای ژورنالهای خارجی برای الگوریتم تشخیص مقاله
با پیشرفت جنبههای مختلف علم، فرآیند داوری (Peer Review) نیز از تکنولوژی روز دنیا عقب نمیماند. برای مبارزه با محتویات نوشته شده توسط ابزارهای AI معمولا سردبیرها و به تبع داورهای مجلات میتوانند مطابق با یک سری اصول ذهنی، مقالهی ساختگی با هوش مصنوعی را شناسایی کنند. این اصول ترکیبی از رویکردهای انسانی و تکنولوژی است تا بتوان مقالات تولید شده توسط هوش مصنوعی را شناسایی کرد. ابتدا رویکردهای انسانی را بررسی میکنیم:

سبکهای نوشتاری غیرمعمول یا مشکوک
متن نوشته شده توسط هوش مصنوعی امکان دارد بسیار پیشرفته باشد، اما ممکن است سبکهای نوشتاری غیرمعمولی داشته باشد که آن را از دست نوشتههای انسانی متمایز میکند. داورها میتوانند از این موضوع بهرهبرداری کرده و به بررسی ناهنجاریهایی مانند تکرار جملات و ساختار نامنظم بپردازند تا استفادهی احتمالی از ابزارهای نوشتاری هوش مصنوعی را شناسایی کنند. همچنین میتوان از نرمافزارهای تشخیص سرقت ادبی مثل آتنتیکا برای تحلیل متن در سطح کلان استفاده کرد.

باز شدن در صفحه دیجیکالا
عدم اصالت
اصالت (Originality)، یک عامل مهم در کیفیت مقالهی تحقیقاتی محسوب میشود. استفاده از هوش مصنوعی در نگارش مقالات دانشگاهی رسما تهدیدی برای اصالت مقالات علمی است؛ به این علت که ابزارهای هوش مصنوعی معمولا شامل عبارات تحریفشده و محتوای سرقتشده در مقاله هستند که استانداردهای اخلاقی آن را تضعیف میکند. علاوه بر این، مقالات تولیدشده توسط هوش مصنوعی ایدهها و نگرش اصلی نویسنده نبوده و ممکن است نتوانند به طور کافی نتایج و به تبع بحث و تفسیر یافتهها را در یک تحقیق توضیح دهند. داوران میتوانند از ابزارهای تشخیص سرقت ادبی برای شناسایی این محتوای غیر اصیل استفاده کنند.
محتوا و نتایج علمی نادرست
با استفاده از ابزارهای تشخیصدهندهی پیشرفته، داوران میتوانند نادرستیها در متن و نتایج تولید شده را با استفاده از ابزارهای نگارش هوش مصنوعی شناسایی کنند. ابزارهای نگارش هوش مصنوعی نمیتوانند همان عمق و ظرافت جامع را به عنوان یک نویسندهی انسانی واقعی ارائه دهند و همین موضوع میتواند یک حفرهی بالقوه باشد که میتوان از آن برای بهبود توانایی در شناسایی مقالات علمی تولید شده توسط هوش مصنوعی بهرهبرداری کرد.

چند الگوریتم تشخیص مقاله مهم توسط نرمافزارهای شناساگر هوش مصنوعی
تشخیصدهندههای AI به بسیاری از همان اصول و فناوریها که تولیدکنندههای متن AI از آنها استفاده میکنند، وابستهاند. یادگیری ماشینی (Machine Learning) و پردازش زبان طبیعی (NLP) از مهمترین آنها هستند؛ چرا که به یک ابزار تشخیص اجازه میدهند تا ورودی را پردازش کرده و بین محتوای تولیدشده توسط AI و محتوای نوشتهشده توسط انسان تمایز قائل شود. این کار میتواند به روشهای مختلفی انجام شود، اما چهار تکنیک در بخش زیر به ویژه در ابزارهای تشخیص محتوای تولید شده توسط AI رایج هستند.
۱. طبقهبندیکنندهها (Classifiers)
همانطور که از نامش پیداست، یک «طبقهبندیکننده»، مدل ML به حساب میآید که دادههای ارائه شده را به دستههای از پیش تعیینشده تقسیم میکند. این مدل معمولا به دادههای آموزشی برچسبگذاریشده وابسته است؛ به این معنی که از مثالهای متنی که قبلا به عنوان نوشتهشده توسط انسان یا AI طبقهبندی شدهاند، یاد میگیرد.
سپس «طبقهبندیکننده» از الگوهای دادههای آموزشی برای طبقهبندی متنهای جدید به طور متناسب استفاده میکند. یک «طبقهبندیکننده» همچنین میتواند از دادههای بدون برچسب استفاده کند، که در این صورت به آن غیرنظارتی گفته میشود. چنین مدلهایی به طور مستقل الگوها و ساختارها را کشف میکنند، که به این معنی است که آنها به منابع کمتری نیاز دارند؛ چرا که نیازی به دادههای برچسبگذاریشده زیاد نیست. از سوی دیگر، طبقهبندهای غیرنظارتی ممکن است به اندازه همتایان نظارتی خود دقیق نباشند.
صرف نظر از نوع، یک «طبقهبندیکننده»، ویژگیهای اصلی محتوای ارائه شده (لحن و سبک، گرامر و غیره) را بررسی میکند. سپس «طبقهبندیکننده»، الگوهای موجود در محتوای تولید شده توسط هوش مصنوعی و آثار نوشته شده توسط انسان را شناسایی میکند تا مرزی بین این دو را ترسیم کند. بسته به مدلی که استفاده میشود، مرز میتواند یک خط، منحنی یا شکل دیگری باشد. برخی از رایجترین الگوریتمهای یادگیری ماشینی که توسط «طبقهبندیکنندهها» استفاده میشود شامل موارد زیر است:

- درختان تصمیم (Decision Trees)
- رگرسیون لجستیک (Logistic Regression)
- جنگل تصادفی (Random Forest)
- ماشینهای وکتور پشتیبان (Support Vector Machines)
هنگامی که تحلیل کامل شد، یک «طبقهبندیکننده» نمرهی اطمینانی را اختصاص میدهد که احتمال تولید متن ارائه شده توسط یک ابزار نوشتن هوش مصنوعی را نشان میدهد.

باز شدن در صفحه دیجیکالا
توجه داشته باشید که نتایج ممکن است همیشه به طور کامل دقیق نباشند؛ چرا که «طبقهبندیکنندهها» میتوانند مثبت کاذب را نشان دهند. به عنوان مثال، اگر یک مدل روی نوع خاصی از نوشتن انسانی آموزش دیده و بیش از حد تطبیق داده شده باشد، ممکن است به شدت به مجموعهی دادههای آموزشی بچسبد و هر چیزی که از آنها منحرف شود را به عنوان تولید شده توسط هوش مصنوعی دستهبندی کند.
برای جلوگیری از چنین مشکلاتی، «طبقهبندیکنندهها» باید به طور منظم بهروزرسانی شوند و تکامل محتوای تولید شده توسط هوش مصنوعی را دنبال کنند.
۲. نمایهسازیها (Embeddings)
نمایهسازی برای نمایش کلمات یا عبارات به عنوان بردارها در یک فضای با ابعاد بالا استفاده میشود. این جمله ممکن است در نگاه اول بسیار عجیب به نظر برسد، اما اگر دو مفهوم را متوجه شوید، درک آن آسان است:
- نمایهسازی (Vector representation): هر کلمه به صورت منحصر به فردی بر اساس معنی و استفادهاش در زبان، نمایهسازی و نقشهبرداری میشود.
- شبکه معنایی (Semantic web of meaning): کلمات با معانی مشابه نزدیکتر به هم قرار میگیرند و یک شبکهی معنایی را تشکیل میدهند.
نمایهسازی بسیار مهم است؛ چرا که مدلهای هوش مصنوعی معنی کلمات را درک نمیکنند، بنابراین باید به اعداد تبدیل شوند و به صورت توضیح داده شده، نمایهسازی شوند. نمایهسازی سپس میتواند به مدلی تبدیل شود که متنهای نوشته شده توسط انسان و هوش مصنوعی را تشخیص دهد. این کار از طریق چندین نوع تحلیل خاص انجام میشود:
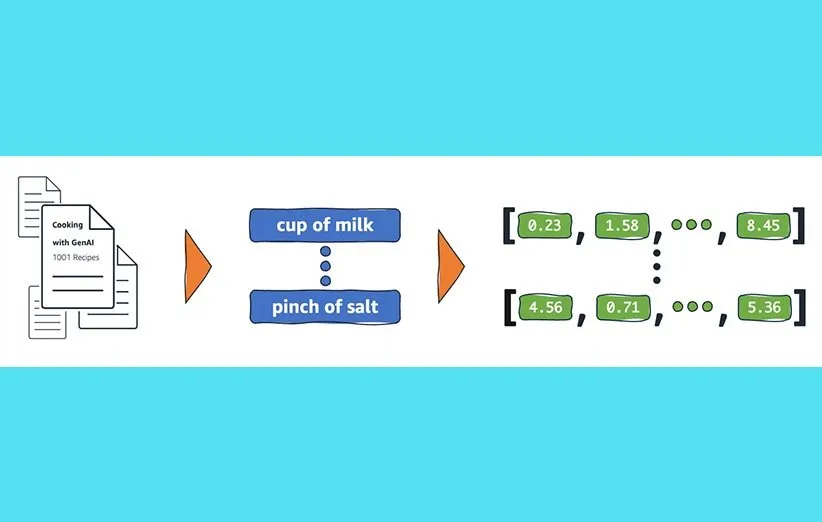
- تحلیل فراوانی کلمات: شناسایی رایجترین یا مکررترین کلمات در یک محتوای خاص.
- تکرار بیش از حد و کمبود تنوع: نشانههای رایج محتوای تولید شده توسط هوش مصنوعی هستند، به این علت که ابزارهای نگارش هوش مصنوعی تمایل دارند به رایجترین کلمات یا عبارات آماری تکیه کنند.
- تحلیل N-gram: فراتر از کلمات فردی میرود تا الگوهای زبانی رایج را ضبط کرده و ساختار عبارات را در یک زمینهی خاص تحلیل کند. نگارش انسانی شامل N-gram های متنوعتر و انتخابهای زبانی خلاقانهتر است، در حالی که یک مدل هوش مصنوعی ممکن است متن را با عبارات کلیشهای بیش از حد پر کند.
- تحلیل نحوی: ساختار گرامری یک جمله را بررسی میکند. ابزارهای هوش مصنوعی معمولا از الگوهای نحوی یکنواخت استفاده میکنند، در حالی که متنهای نوشته شده توسط انسان، نشاندهندهی پیچیدگی نحوی بیشتر و ساختارهای جملات متنوعتر هستند.
- تحلیل معنایی: معنی کلمات و عبارات را تحلیل میکند و به استعارهها، تداعیها، ارجاعات فرهنگی و سایر ظرافتها توجه میکند. محتوای هوش مصنوعی اغلب این ظرافتها را نادرست تفسیر میکند یا به طور کلی از متن حذف میکند، در حالی که یک اثر نوشته شده توسط انسان، نشاندهندهی عمق بیشتری از معنی خاص به زمینه است.
تشخیص محتوای تولید شده توسط هوش مصنوعی موثر شامل ترکیبی از این تحلیلها است که میتواند منابع زیادی را مصرف کند. دادههای با ابعاد بالا نیز بسیار پیچیده هستند. تجسم و تفسیر نمایهسازیها میتواند با صدها یا هزاران بعد دشوار باشد. این رویه نیاز به سادهسازی و کاهش ابعاد دارد که کار آسانی نیست.

باز شدن در صفحه دیجیکالا
۳. مولفهای به اسم پرپلکسیتی (Perplexity)
پرپلکسیتی در لغت به «گیجی» معنی میشود اما در بحث هوش مصنوعی، معنای خاصی دارد. پرپلکسیتی یک مقیاس منحصربهفرد تلقی میشود که یک هوش مصنوعی در مواجهه با یک متن جدید تا چه اندازه به زبان عامیه سورپرایز میشود.

هر اندازه این مولفه امتیاز بیشتری را به یک متن دهد، احتمال بیشتری وجود دارد که مطلب توسط یک انسان نوشته شده باشد. البته در حال حاضر این موضوع مورد پذیرش قرار گرفته که الزاما هر متنی که امتیاز پرپلکسیتی آن بالا باشد، الزاما توسط انسان نوشته نشده است. برای مثال در نظر داشته باشید که مطلب با جملات زائد و غیر منطقی نوشته شده باشد. در این وضعیت نیز ابزارهای شناساگر هوش مصنوعی فکر میکنند مطلب توسط انسان نوشته شده است؛ چرا که امتیاز پرپلکسیتی آن بالاست. بنا به همین دلایل، صرفا با تکیه بر مولفهی پرپلکسیتی نمیتوان اصالت یک محتوا را سنجید.
۴. مولفه Burstiness
پارامتر Burstiness شبیه به مولفه پرپلکسیتی است اما به جای تمرکز روی یک سری کلمات خاص، روی کل جملات مانور میدهد. این ویژگی تغییرات کلی در ساختار جملات، طول و پیچیدگی متن را اندازهگیری میکند؛ چرا که این ویژگیها میتوانند بین متنهای تولید شده توسط هوش مصنوعی و متنهای نوشته شده توسط انسان به شدت متفاوت باشند.

ابزارهای تولید کنندهی محتوای هوش مصنوعی تمایل دارند متنی یکنواختتر با نوسان کمتر را تولید کنند؛ آنها میتوانند کلمات یا عبارات خاص را به طور مکرر تکرار کنند. به همین دلیل، معمولا متون نوشته شده توسط AI مثل ذهن انسان چندان خلاقانه نیستند. یک انسان میتواند جملات را با طولهای بلند و حتی کوتاه بنویسد و پیچیدگی جملات نیز اصلا یکنواخت نیست. مجموعهای از این ویژگیها را تحت عنوان Burstiness مینامند. هر اندازه این مولفه بیشتر باشد، احتمالا مطلب توسط انسان نوشته شده است. با این حال، شبیه به پرپلکسیتی، از مولفهی چهارم نیز نباید به تنهایی استفاده کرد؛ چرا که شما با یک دستور خوب میتوانید یک هوش مصنوعی را راهنمایی کنید تا متنهای پیچیدهتری را با ساختارهای جملات متنوع ایجاد کند، که ممکن است ابزار شناساگر را که بیش از حد به ناهمگونی وابسته است، فریب دهد.

باز شدن در صفحه دیجیکالا
آیا حافظه موقت هوش مصنوعی در اختیار کسی قرار میگیرد؟
احتمالا این مسئله برای بسیاری از نویسندگان هنگام کار با هوشهای مصنوعی مولد مثل هوش مصنوعی ChatGPT شکل گرفته که آیا نوشتههای تولید شده توسط هوش مصنوعی که در حافظهی موقت آن ذخیره میشود، در اختیار افراد یا سازمانهای دیگر قرار میگیرد یا خیر. ما ابتدا این سوال را از هوش مصنوعی ChatGPT پرسیدیم که پاسخ آن در تصویر زیر مشخص است:
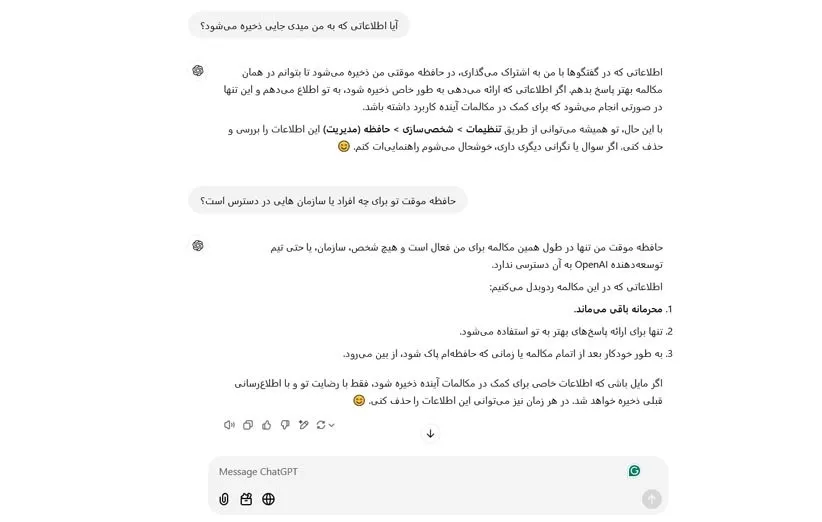
به طور کلی ابزارهای مشابه به ChatGPT دارای یک فرم حافظهی پنهان (Cache) هستند که برای چت جی پی تی تحت عنوان Prompt caching شناخته میشود. ابزارهای هوش مصنوعی با کمک این ویژگی میتوانند پاسخهای سریعتری را ارائه دهند. هر چند همانطور که در تصویر بالا نیز گفته شده، حافظهی پنهان صرفا روی سرور بوده و هیچ فردی به این دسته از اطلاعات دسترسی پیدا نمیکند. همچنین به گفتهی شرکت OpenAI کشها پس از نهایت یک ساعت بلا استفاده بودن از سرور برای همیشه پاک میشود. بنابراین، اطلاعات موجود در دستورها بین شرکتها و سازمانها پخش نمیشود. حداقل این بیانیهای است که توسط شرکت OpenAI سازندهی چت جیپیتی اعلام شده است.
با توجه موارد گفته شده، بعید به نظر میرسد که اطلاعات به دست آمده از ابزارهای هوش مصنوعی به همین راحتی توسط انتشارات و مجلات خریداری شود. حداقل سناریوی خرید و فروش اطلاعات توسط شرکتهای هوش مصنوعی در زمان فعلی چندان منطقی و از جنبهی اقتصادی به صرفه نیست.
الگوریتمهای هوش مصنوعی برای تشخیص تصاویر و نمودارهای مقاله دانشگاهی
ابزارهای هوش مصنوعی در زمان فعلی به قدری پیشرفته شدهاند که حتی امکان ساخت تصاویر را هم دارند. با این اوصاف، ابزار تشخیصدهندهی AI میتوانند تصاویر ساخته شده با هوش مصنوعی را نیز به راحتی تشخیص دهند. البته نه صرفا ابزارهای نرم افزاری، بلکه داوران مجلات هم میتوانند اشکال و تصاویر علمی تولید شده توسط هوش مصنوعی را با بررسی ناهماهنگیها در دادهها، الگوهای غیرواقعی، کمبود جزئیات مرتبط، سبکهای بصری غیرمعمول و حتی اختلافات با دانش ثبت شده در این زمینه به راحتی بررسی کنند. در حال حاضر میتوان با توجه به سبک تصاویر به راحتی شک کرد آیا یک هوش مصنوعی آن را ساخته است یا خیر. به طور کلی ابزارهای شناساگر تصاویر خلق شده با هوش مصنوعی یک یا چند مورد از مولفههای زیر را بررسی میکنند:

ناهماهنگیهای داده
- توزیع یا الگوهای غیرواقعی دادهها در جداول و نمودارها
- نداشتن نوار خطای استاندارد یا اندازههای ضد و نقیض با یافتههای مقاله
- نقاطی که به نظر میرسد به طور مصنوعی تولید شده یا تکرار شدهاند.
ناهنجاریهای بصری
- کیفیت تصویر غیرطبیعی، پیکسلسازی یا آرتیفکتهای هنری که نشاندهندهی دستکاری هستند.
- عناصر بصری یا انتخاب استایلها و سبکهای ناآشنا با حوزهی دانشگاهی
- یکنواختی بیش از حد تصاویر موجود در مقاله

باز شدن در صفحه دیجیکالا
ناهماهنگیهای زمینهای
- شکلهایی که با توصیف متن یا روایت کلی تحقیق همراستا نیستند.
- برچسبها یا یادداشتهایی که شامل ناهماهنگیها یا اطلاعات نادرست هستند.
- کمبود جزئیات لازم یا اطلاعات مهم در تصاویر و اشکال.
تحلیل متاداده
- بررسی فرمت فایل و تاریخ ایجاد برای شناسایی نشانههای احتمالی دستکاری.
- بررسی نرمافزاری که برای تولید شکل استفاده شده است؛ البته اگر این اطلاعات توسط نویسنده ارائه شده باشد.
مقایسه با دانش موجود
- بررسی اینکه آیا نتایج ارائه شده در شکل با درک علمی در این حوزه همراستا است.
- مقایسه شکل با دادههای مشابه منتشر شده در سایر مقالات در این حوزه.
ابزارهای شناساگر محتوای هوش مصنوعی چقدر دقیق هستند؟
این احتمال نیز وجود دارد که ابزارهای شناساگر محتوای هوش مصنوعی به اشتباه یک تصویر یا متن را مصنوعی تلقی کنند. به هر ترتیب، شانس بروز خطا در هر ابزاری حتی شناساگرهای هوش مصنوعی جمینای و ChatGPT نیز وجود دارد. سوال اینجاست این ابزار تا چه اندازه دقیق هستند و تا چه میزان میتوان به قدرت نرم افزارهای فعلی اعتماد کرد؟
تشخیصدهندههای محتوای هوش مصنوعی در حالی که بدون شک در تشخیص محتوای تولید شده توسط هوش مصنوعی مفید هستند، شما باید نتایج آنها را برای دقت بیشتر به صورت دستی بررسی کنید. برای مثال یکی از کاربران در تصویر زیر اعلام کرده که از سه ابزار مختلف برای تشخیص استفاده کرده و هر یک از آنها نتیجهی متفاوتی را اعلام کرده است.
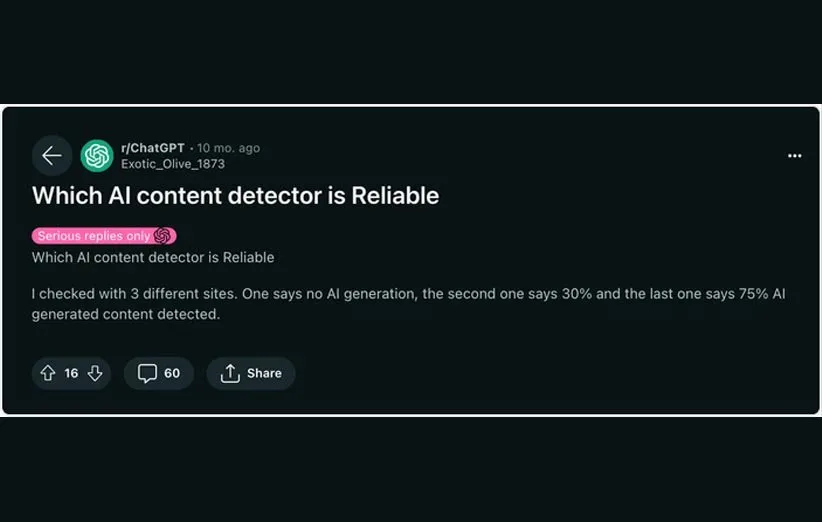
مانند ابزارهای هوش مصنوعی تولیدی، تشخیصدهندههای هوش مصنوعی هنوز در مراحل ابتدایی خود هستند و به طور مداوم در حال تکامل هستند. دلایل متعددی برای این موضوع وجود دارد که بارزترین آنها تفاوتهای زبانی و خلاقیت تلقی میشود. تشخیصدهندههای هوش مصنوعی، زبان را به خوبی انسانها درک نمیکنند. آنها تنها به دادههای تاریخی از مجموعههای آموزشی خود برای پیشبینیها به طور حداکثری اعتماد میکنند. به همین دلیل، نتیجه همیشه دقیق نیست، بنابراین ممکن است با اطلاعات مثبت کاذب و منفیهای کاذب مواجه شوید.
یکی از چالشهای قابل توجه، تکامل سریع تولیدکنندههای متن هوش مصنوعی است که امکان دارد تشخیصدهندههای هوش مصنوعی نتوانند به آن برسند. برخی از تولیدکنندههای محتوای پیشرفته هوش مصنوعی در حال حاضر ادعا میکنند که به طور قابل توجهی میتوانند از تشخیص هوش مصنوعی عبور کرده و مرز بین محتوای انسانی و هوش مصنوعی را بیشتر محو کنند. با این حال، بسیاری از افراد به شدت به هوش مصنوعی برای ایجاد محتوا وابسته هستند که میتواند مشکلات مختلفی را ایجاد کند. انتشار محتوای تولید شده توسط هوش مصنوعی بدون تایید یک هوش انسانی میتواند منجر به نشر اطلاعات نادرست شود.
با این حال، استفاده از یک تشخیصدهندهی هوش مصنوعی به مراتب بهتر از تشخیص نوشتار هوش مصنوعی به صورت دستی است؛ چرا که این کار بسیار زمانبر بوده و حتی برای نویسندههای باتجربه و با مهارت بالا نیز میتواند چالشبرانگیز باشد.

منبع: دیجیکالا مگ
سوال و جوابهای رایج
آیا برای مقاله دانشگاهی میتوان از تصاویر هوش مصنوعی استفاده کرد؟
خیر. ژورنالها متوجه ساختگی بودن تصاویر میشوند.
آیا برای مقاله دانشگاهی میتوان از متن تولید شده به زبان انگلیسی توسط هوش مصنوعی استفاده کرد؟
خیر. ژورنالها متوجه کپی بودن متن توسط هوش مصنوعی میشوند.
ژورنالهای خارجی از چه برنامهای برای تشخیص اصالت مقاله به زبان انگلیسی استفاده میکنند؟
معمولا نرم افزار آتنتیکا یکی از بهترین و دقیقترینها محسوب میشود.
