
یادگیری تقویتی چیست و چه کاربردهایی دارد؟

یادگیری تقویتی (Reinforcement Learning) بخشی از یادگیری ماشین است که تلاش میکند کارهایی انجام دهد تا دستاورد موقعیتهای خاص به حداکثر برسد. هدف الگوریتمهای یادگیری تقویتی این است که بهترین کاری که میشود در یک موقعیت خاص انجام داد را پیدا کنند. این نوع یادگیری ماشین میتواند یاد بگیرد حتی در محیطهای پیچیده و غیر مطمئن هم فرآیند یادگیری را انجام دهد و به اهدافش دست پیدا کند. این سیستم، درست مانند مغز انسان برای انتخابهای خوب پاداش میگیرد، برای انتخابهای بد جریمه میشود و از هر انتخاب یاد میگیرد.

سادهترین مدل ذهنی که میتواند به درک یادگیری تقویتی کمک کند یک بازی ویدیویی است. جالب است بدانید الگوریتمهای یادگیری تقویتی در بازیهای ویدیویی نقش برجستهای دارند. در یک بازی ویدیویی معمولی شما عناصر زیر را دارید؛
- یک مأمور (بازیکن) که کارهای مختلفی انجام میدهد
- کارهایی که مأمور باید انجام دهد (حرکت در فضا به بالا، خرید یک وسیله یا هرچیز دیگری)
- پاداش مأمور (سکه، از بین رفتن دشمن و…)
- محیطی که مامور در آن قرار دارد (یک اتاق، یک نقشه و…)
- حالت خاصی که مأمور در حال حاضر در آنجاست (قسمت خاصی از اتاق، بخش مشخصی از نقشه مثلا کنار یک میدان)
- هدفی برای مأمور که به با دست یابی به آن به بیشترین پاداش ممکن میرسد
همین عناصر دقیقا سازندگان یادگیری تقویتی هم هستند (شاید یادگیری ماشین در حقیقت یک بازی است.) در یادگیری تقویتی ما یک مأمور را در بهصورت مرحله به مرحله در یک محیط راهنمایی میکنیم و اگر کارش را در هر مرحله درست انجام دهد به او پاداش میدهیم. تا به حال اصطلاح فرآیند تصمیمگیری مارکوف (Markov Decision Process) را شنیدهاید؟ این همان چیزی است که میتواند بهخوبی این تنظیم دقیق را توصیف کند.
برای تصویرسازی بهتر یک موش را درون یک ماز تصور کنید؛

اگر خودتان داخل این ماز پر پیچ و خم باشید و هدفتان دستاورد بیشتر، یعنی جمعآوری مقدار بیشتری آب و پنیر باشد محاسبه میکنید چطور به پاداشهای بیشتری دسترسی خواهید داشت. برای مثال اگر سه پاداش در سمت راست شما و یک پاداش در سمت چپتان باشد چه میکنید؟ حتما به سمت راست خواهید رفت.
این شیوهای است که یادگیری تقویتی با آن کار میکند. در هر حالت همهی اقدامات ممکن، در این حالت رفتن به چپ، راست، بالا یا پایین را محاسبه میکند و عملی را انجام میدهد که بهترین نتیجه را داشته باشد. اگر این فرآیند چند بار تکرار شود موش دیگر باید بهترین مسیر را بشناسد.
اما دقیقا چطور تصمیم میگیرید بهترین نتیجه کدام است؟
فرآیند تصمیم گیری در یادگیری تقویتی
دو روش عمده برای آموزش تصمیمگیری صحیح در محیطهای یادگیری تقویتی وجود دارد؛
- یادگیری سیاست یا خط مشی
- Q-Learning / تابع ارزش (Value Function)
یادگیری سیاست (Policy Learning)
یادگیری سیاست یا خط مشی باید بهعنوان نوعی دستورالعمل کاملا مفصل در نظر گرفته شود. خطی مشی دقیقا به مأمور میگوید در هر وضعیت باید چه کاری انجام دهد. بخشی از سیاست ممکن است چنین چیزی باشد: «اگر با دشمن روبهرو شدید و دشمن از شما قویتر بود، عقبنشینی کنید» اگر به سیاستها بهعنوان یک تابع نگاه کنید تنها یک ورودی دارد؛ وضعیت. اما دانستن اینکه باید از چه سیاستی استفاده کنید آسان نیست و نیاز به دانش عمیق و کافی از تابع پیچیدهای دارد که نقشه را به سمت هدف پیش میبرد.
تحقیقات جالبی دربارهی به کارگیری یادگیری عمیق برای یادگرفتن سیاستها در سناریوهای یادگیری تقویتی انجام شده است. Andrej Karpathy از یک شبکهی عصبی استفاده کرده است تا بازی کلاسیک pong را به یک مأمور یاد بدهد. این چندان شگفتآور نیست چرا که میدانیم شبکههای عصبی در شرایط پیچیده هم عملکرد بسیار خوبی دارند.
Q-Learning – تابع ارزش
یکی دیگر از راههای راهنمایی مأموری که در نظر گرفتیم این است که به جای اینکه به او بگوییم در هر مرحله دقیقا چه کاری انجام دهد به او یک چارچوب کاری بدهیم تا تصمیماتش را خودش بگیرد. برخلاف روش یادگیری سیاست، Q-Learning دو ورودی دارد؛ وضعیت و عمل(action). اگر در یک تقاطع قرار بگیرید Q-Learning ارزش انتظاری هر یک از کارهایی که مأمور شما میتواند انجام دهد به شما میگوید (به چپ برود، به راست برود و یا هرچیز دیگری).
یکی از چیزهایی که باید دربارهی Q-Learning بدانید این است که این روش تنها ارزش فوری انجام یک عمل در یک وضعیت داده شده را تخمین نمیزند، بلکه ارزشهای بالقوهای که ممکن است بر اثر انجام کارهای فعلی ایجاد شود را هم در نظر میگیرد.
برای کسانی که با امور مالی شرکتها آشنا هستند Q-Learning شبیه تحلیل تخفیف جریان نقدی (Discounted Cash Flow) است یعنی تمام ارزش بالقوهی آینده را در هنگام تعیین ارزش فعلی یک عمل (دارایی) در نظر میگیرد. در حقیقت Q-Learning هم از یک فاکتور تخفیف کمک میگیرد تا نشان دهد پاداشها در آینده ارزش کمتری از زمان حال دارند.
یادگیری خط مشی و Q-Learning دو روش اصلی برای هدایت مأمور در یادگیری تقویتی هستند اما در حال حاضر تعدادی رویکرد جدید هم به کمک یادگیری عمیق به وجود آمده است که میتواند با این دو رویکرد ترکیب شود یا راهحل خلاقانهی دیگری به وجود بیاورد.
DeepMind مقالهای دربارهی استفاده از شبکههای عصبی (که آنها را Deep Q-networks نامگذاری کرده است) برای تقریب توابع Q-Learning منتشر کرد و به نتایج قابل توجهی هم رسید. چند سال بعد، یک روش پیشگام که به نام A3C شناخته میشود دو دیدگاه یادگیری سیاست و Q-Learning را باهم ترکیب کرد.
اضافه کردن شبکههای عصبی به هر چیزی میتواند آن را پیچیده کند. به خاطر داشته باشید همهی این رویکردهای یادگیری یک هدف ساده دارند؛ راهنمایی مؤثر مأمور شما در محیط و دستیابی به بهترین پاداش، فقط همین.
کاربردهای یادگیری تقویتی
گرچه در طول دهههای گذشته مفاهیم از یادگیری تقویتی حمایت و پشتیبانی کردهاند اما متأسفانه تا به امروز کمتر از آن به صورت عملی استفاده شده است. چند دلیل برای این مسأله وجود دارد اما همهی آن تابع یک چیز هستند؛
یادگیری تقویتی تلاش میکند تا الگوریتم های دیگر را برای انجام وظایف خوش-تعریف به طور مؤثری تغییر دهد.
به همین دلیل هنگامی که محیط یادگیری ماشین نامشخص و پیچیده است بهترین کار استفاده از یادگیری تقویتی است.
بیشترین کاربرد عملی یادگیری تقویتی در دهههای گذشته بازیهای ویدیویی بوده است. الگوریتمهای یادگیری تقویتی که با نام Cutting Edge شناخته میشوند نتایج مؤثری در بازیهای مدرن و کلاسیک به دست آوردهاند که توانسته است رقبای انسانی را به شکل قابل توجهی کنار بزند. بازیهای ویدیویی مجموعههای پیچیدهی بسیار جذابی برای الگوریتمهای یادگیری تقویتی هستند.
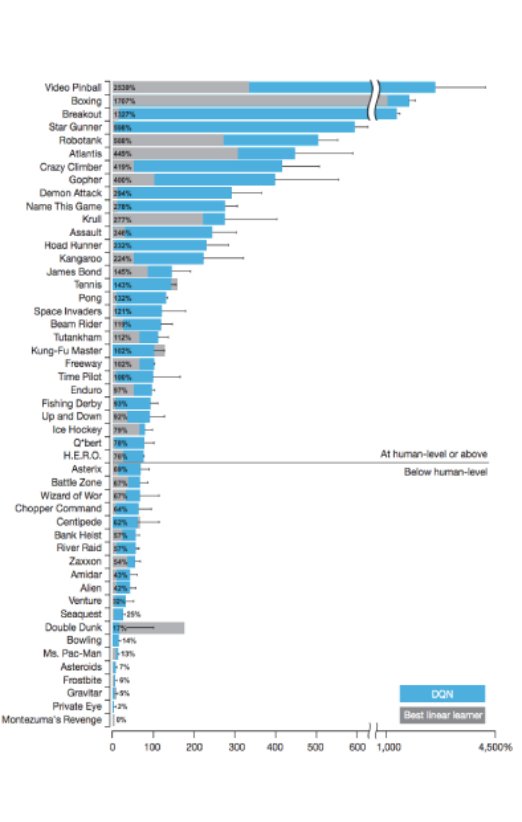
این نمودار در یکی از مقالات DeepMind منتشر شده است. برای بیش از نیمی از بازیهایی که امتحان شدهاند بازیکن توانسته است معیارهای انسانی را اجرا کند و حتی سطح مهارتی دوبرابر بالاتر نشان داده است. البته برای بعضی از بازیها هم الگوریتمها حتی به عملکرد انسانی نزدیک هم نبودهاند.
حوزهی دیگری که یادگیری تقویتی موفقیتهای عملی در آن به دست آورده اتوماسیون صنعتی و رباتیک است. رباتها بهسادگی میتوانند مانند مأمور یا بازیکن در محیط در نظر گرفته شوند و یادگیری تقویتی نشان داده است یک راه حل عملی برای آموزش است.
گوگل به کمک یادگیری تقویتی توانسته است در کاهش هزینههای مراکز دادهی خود پیشرفت کند. آنها از یادگیری تقویتی برای کاهش انرژی استفاده شده برای خنک کنندهها و در نتیجه کل انرژی مصرفی استفاده کردهاند.
بهداشت و آموزش هم زمینههای دیگری هستند که یادگیری تقویتی در آنها استفاده شده است. البته بیشتر کارهایی که تا این لحظه در این زمینهها انجام شده است تحقیقات دانشگاهی بودهاند. این روش یادگیری ماشین میتواند به انتخاب بهترین درمان و بهترین دارو برای بیماران کمک کند و مربی جذابی هم باشد. یادگیری ماشینی پیشرفتهای جالبی در سالهای گذشته داشته است.
چالشهای کار با یادگیری تقویتی
هرچند یادگیری تقویتی پیشرفتهای بسیار امیدوارکنندهای داشته است اما کار با آن همچنان بسیار دشوار است.
مسألهی اول دادهها است. یادگیری تقویتی برای رسیدن به دقت کافی نیازمند حجم زیادی داده برای آموزش است در حالی که سایر الگوریتمها سریعتر به این سطح از دقت میرسند. برای مثال RainbowDQN به ۱۸ میلیون فریم از بازیهای آتاری یا ۸۳ ساعت بازی برای آموزش نیاز دارد. انسان خیلی سریعتر میتواند این کار را انجام دهد.
چالش دیگری که در کار با یادگیری تقویتی وجود دارد مشکل دامنه اختصاصی است. یادگیری تقویتی یک الگوریتم عمومی است که از دیدگاه نظری باید بتواند برای تمام مسائل راهحل پیدا کند. اما همهی این مسائل راهحلهای خاصی دارند که بهتر از یادگیری تقویتی کار میکنند مثلا بهینهسازی آنلاین مسیر برای رباتهای MuJuCo.
در آخر مهمترین مسألهای که دربارهی یادگیری تقویتی وجود دارد طراحی تابع پاداش است. اگر طراحان الگوریتم کسانی هستند که پاداشها را تعیین میکنند بنابراین نتایج مدل بهشدت تحت تأثیر طراحان خواهد بود.
حتی زمانی که تابع پاداش بهخوبی تنظیم شده باشد، باز هم یادگیری تقویتی این راه هوشمندانه را دارد که روشهایی شبیه به آنچه شما میخواهید را بیابد و به آن عمل کن که در عمل این موضوع یک مسألهی جدی است. زیرا نتیجه این است که در حالتهای بهینهی موضعی گیر میافتیم و به روشها و نتایج جدیدی که باید سیستم بتواند پس از یادگیری برسد، نخواهیم رسید.
انتظار میرود تحقیقات در حال انجام بتوانند در طول زمان موانعی که سر راه یادگیری تقویتی وجود دارد را بردارند و امکان استفادهی بهتر و بیشتر از این فناوری را فراهم کنند.
